After 3 betas and 3 release candidates, Julia version 1.9 has finally(!) been released. We would like to thank all the contributors to this release and all the testers that helped with finding regressions and issues in the pre-releases. Without you, this release would not have been possible.
The full list of changes can be found in the NEWS file, but here we'll give a more in-depth overview of some of the release highlights.
- Caching of native code
- Package extensions
- Heap snapshot
- Memory usage hint for the GC with
--heap-size-hint - Sorting performance
- Tasks and the interactive thread pool
- REPL
- DelimitedFiles – first stdlib to be upgradable
--math-mode=fastdisabled- Pkg
pkg> up Foowill now try to only updateFoopkg> addwill only auto update the registry once per daypkg> addcan now try to only add already installed packagespkg> whyto tell you why a package is in the manifestpkg> test --coverage(the default for CI) is now faster- Better support for sub-packages in monorepos via the
manifestfield inProject.toml
- Apple Silicon Achieves Tier 1 Status
- LLVM Update to v14
- Native half-precision floating-point arithmetic
Caching of native code
Tim Holy, Jameson Nash, and Valentin Churavy
In Julia, precompilation involves compiling package code and saving the compiled output to disk as a "cache file" for each package. This process significantly reduces the time needed for compilation when using the package, as you only need to build it once and can reuse it multiple times.
However, prior to Julia 1.9, only a portion of the compiled code could be saved: types, variables, and methods were saved, as well as the outputs of any type-inference for the argument types specifically precompiled by the package developers. Notably absent from cache files was the native code—the code that actually runs on your CPU. Although caching helped reduce time-to-first-execution (TTFX) latency, the need to regenerate native code in each session meant that many packages still suffered from long TTFX latencies.
With the introduction of Julia 1.9, native code caching is now available, resulting in a significant improvement in TTFX latency and paving the way for future enhancements across the ecosystem. Package authors can now utilize precompile statements or workloads with PrecompileTools to cache important routines in advance. Users can also create custom local "Startup" packages that load dependencies and precompile workloads tailored to their daily work.
This feature comes with some tradeoffs, such as an increase in precompilation time by 10%-50%. However, since this is a one-time cost, we believe the tradeoff is well worth it. Cache files have also become larger due to the storage of more data and the use of a different serialization format.
The graph below illustrates the changes in time-to-load (TTL), TTFX, and cache file size starting with Julia 1.7 (prior to any of the recent precompilation improvements):
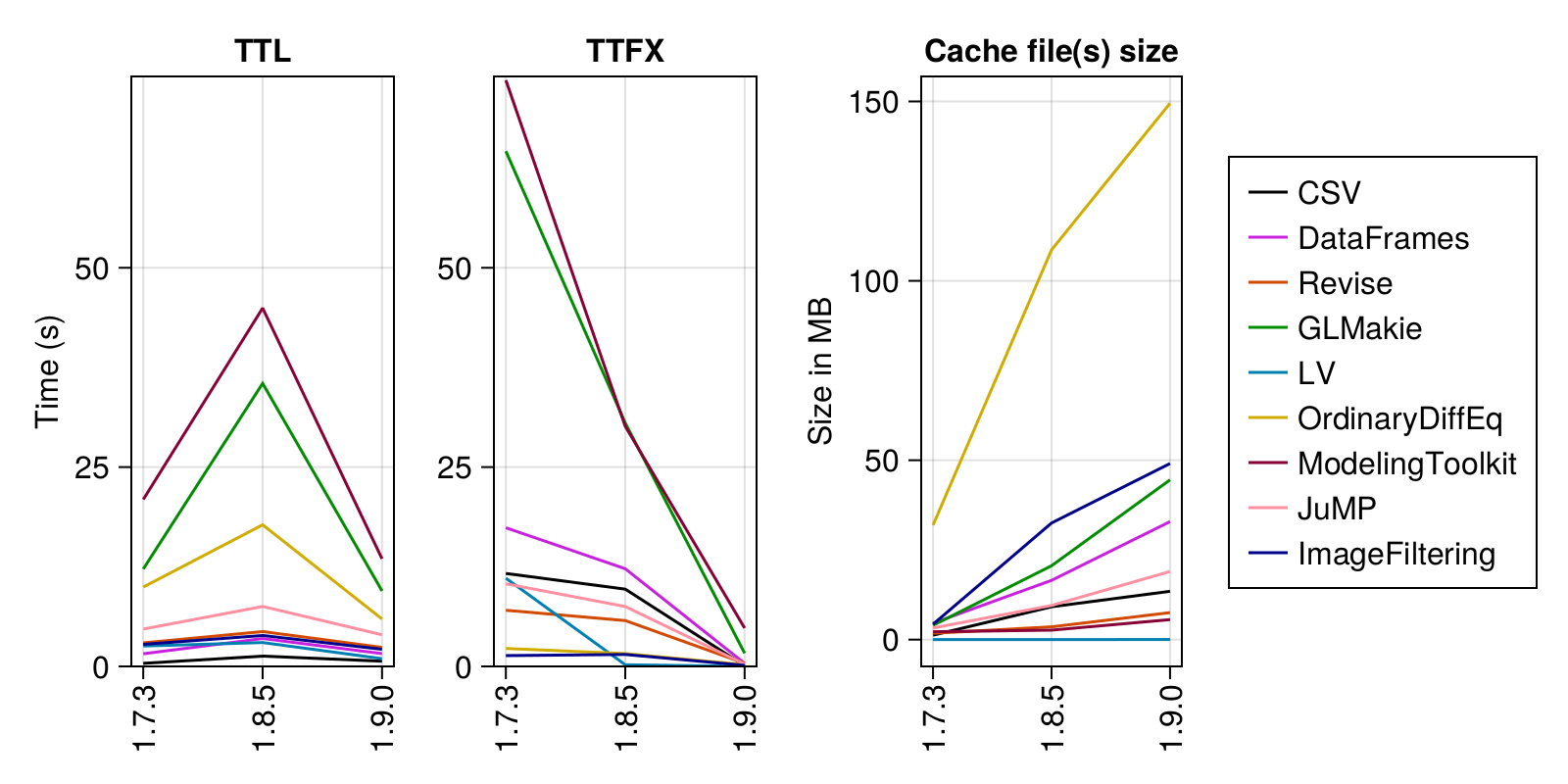
(See Methodology below for details.) For most packages, TTFX has gone from being the dominant factor to virtually negligible. TTL has also been reduced, albeit not as dramatically as TTFX. The same data is presented in the table below, with the "ratio" columns representing the ratio of Julia 1.7 / Julia 1.9 and "total" meaning "TTL + TTFX".
| package | TTFX_1.7 [s] | TTFX_1.9 [s] | TTFX_ratio | TTL_1.7 [s] | TTL_1.9 [s] | TTL_ratio | total_ratio |
|---|---|---|---|---|---|---|---|
| CSV | 11.66 | 0.08 | 137.43 | 0.38 | 0.65 | 0.59 | 16.34 |
| DataFrames | 17.39 | 0.38 | 45.99 | 1.59 | 1.6 | 0.99 | 9.58 |
| Revise | 7.04 | 0.39 | 18.2 | 2.95 | 2.38 | 1.24 | 3.61 |
| GLMakie | 64.62 | 1.66 | 39.02 | 12.21 | 9.47 | 1.29 | 6.91 |
| LV | 11.06 | 0.0 | 7677.8 | 2.56 | 0.97 | 2.64 | 14.05 |
| OrdinaryDiffEq | 2.25 | 0.21 | 10.67 | 9.95 | 5.95 | 1.67 | 1.98 |
| ModelingToolkit | 73.53 | 4.81 | 15.3 | 20.93 | 13.5 | 1.55 | 5.16 |
| JuMP | 10.36 | 0.28 | 36.75 | 4.68 | 3.96 | 1.18 | 3.54 |
| ImageFiltering | 1.35 | 0.12 | 10.84 | 2.76 | 2.14 | 1.29 | 1.82 |
These numbers reveal a huge quality-of-life improvement across a wide range of packages.
Together with PrecompileTools.jl, Julia 1.9 delivers many of the benefits of PackageCompiler without the need for user-customization. Here is an explicit comparison:
| Task | Julia 1.9 + PrecompileTools | PackageCompiler |
|---|---|---|
| Developers can reduce out-of-box TTFX for their users | ✔️ | ❌ |
| Users can reduce TTFX for custom tasks | ✔️ | ✔️ |
| Packages can be updated without rebuilding system image | ✔️ | ❌ |
| Reduces TTL | ❌ | ✔️ |
The difference in TTL arises because the system image can safely skip all the code-validation checks that are necessary when loading packages.
At the time of Julia 1.9's release, only a small fraction of the package ecosystem has adopted PrecompileTools. As these new tools become leveraged more widely, users can probably expect ongoing improvements in TTFX.
Methodology
A demonstration workload was designed for each package. That workload was placed in a Startup package and precompiled; for benchmarking, we load the Startup package and run the same workload. Full details can be found in this repository.
Package extensions
Kristoffer Carlsson
In Julia, the power of multiple dispatch makes it simple to extend functionality across a wide range of types. For instance, a plotting package may want to provide functionality to plot a large variety of Julia objects, many of which are defined in separate packages within the Julia ecosystem. Moreover, it's possible to add optimized versions of generic functions for specific types, such as the StaticArray, where the array size is known at compile time, leading to significant performance improvements.
To extend a method to a type, you would typically import the package containing the type, load the package to access the type, and then define the extended method. Taking the use case of the plotting package, this could look something like:
import Contours
function plot(contour::Countours.Contour)
...
endHowever, adding package dependencies can have costs, such as increased load times or require installation of large artifacts (e.g., CUDA.jl). This can be burdensome for package authors who must constantly balance dependency costs against the benefits of new method extensions for an "average" package user.
Julia 1.9 introduces "package extensions", a feature that, in a loose sense, automatically loads a module when a set of packages are loaded. The module, contained within a file in the ext directory of the parent package, loads the "weak dependency" and extend methods. The goal is that one should not have to pay for features that one does not use. Package extensions provide functionality similar to that which Requires.jl already offers but with key advantages, such as allowing precompilation of conditional code and adding compatibility constraints on weak dependencies. Since the package extension functionality is now "first class", package authors should be less reluctant to start using it compared to Requires.jl. Package extensions can be introduced in a fully backwards compatible manner where one can either chose to use Requires.jl or make the weak dependency into a normal dependency on earlier Julia versions.
As a concrete example where package extensions are used for good effect, the ForwardDiff.jl package provides optimized routines for automatic differentiation when the input is a StaticArray. In Julia 1.8, it unconditionally loaded the StaticArrays package, while in 1.9, it uses a package extension. This results in a significant improvement in load time:
# 1.8 (StaticArrays unconditionally loaded)
julia> @time using ForwardDiff
0.590685 seconds (2.76 M allocations: 201.567 MiB)
# 1.9 (StaticArrays not loaded)
julia> @time using ForwardDiff
0.247568 seconds (220.93 k allocations: 13.793 MiB)For a comprehensive guide on using package extensions, please refer to the documentation.
Heap snapshot
Apaz-Cli, Pete Vilter, Nathan Daly, Valentin Churavy, Gabriel Baraldi, and Ian Butterworth
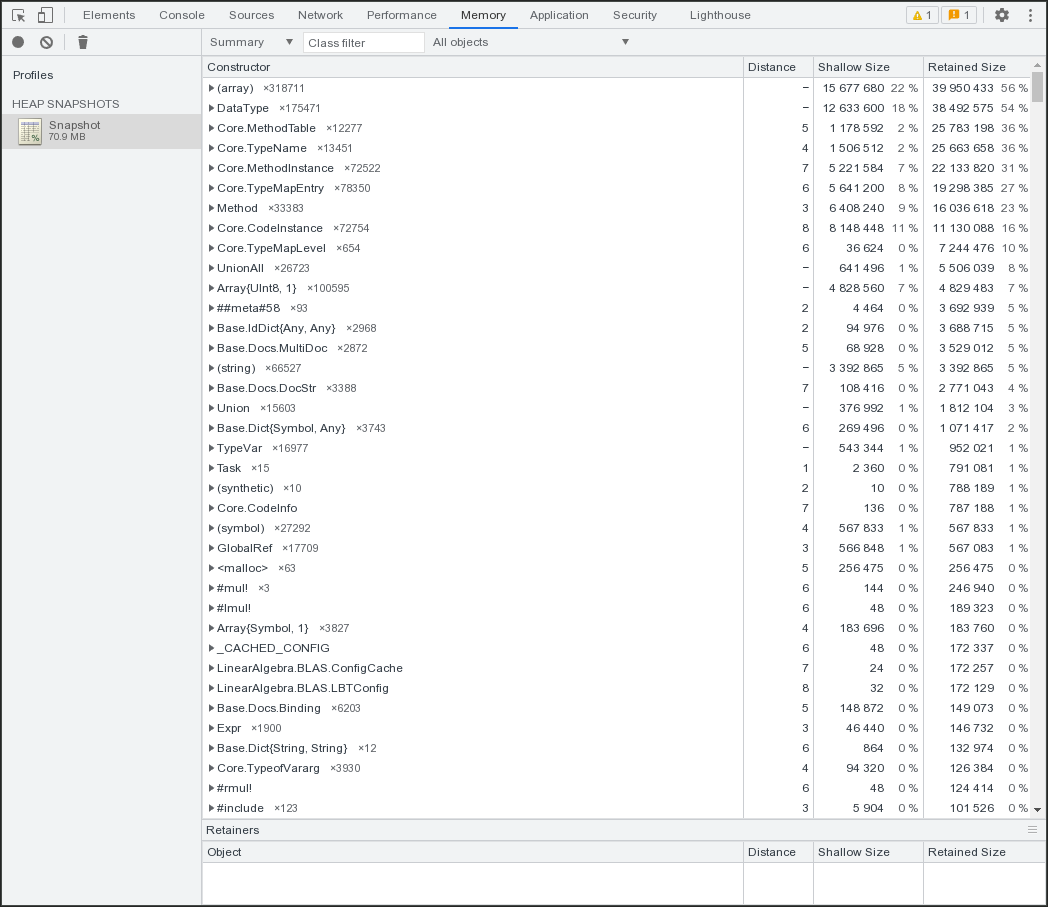
Are you curious about how your memory is being utilized in your Julia programs? With the introduction of Julia 1.9, you can now generate heap snapshots that can be examined using Chrome DevTools.
To create a heap snapshot, simply utilize the Profile package and call the take_heap_snapshot function, as demonstrated below:
using Profile
Profile.take_heap_snapshot("Snapshot.heapsnapshot")If you are more interested in the number of objects rather than their sizes, you can use the all_one=true argument. This will report every object's size as one, making it easier to identify the total count of objects retained.
Profile.take_heap_snapshot("Snapshot.heapsnapshot", all_one=true)To analyze your heap snapshot, open a Chromium browser and follow these steps: right click -> inspect -> memory -> load. Upload your .heapsnapshot file, and a new tab will appear on the left side to display your snapshot's details.
Memory usage hint for the GC with --heap-size-hint
Roman Samarev
Julia 1.9 introduces a new command flag, --heap-size-hint=<size>, that enables users to set a limit on memory usage, after which the garbage collector (GC) will work more aggressively to clean up unused memory.
By specifying a memory limit, users can ensure that the garbage collector more proactively manages memory resources, reducing the risk of running out of memory.
To use this new feature, simply run Julia with the --heap-size-hint flag followed by the desired memory limit:
julia --heap-size-hint=<size>Replace <size> with the appropriate value (e.g., 1G for 1 gigabyte or 512M for 512 megabytes).
This enhancement in Julia 1.9 makes it easier than ever to manage memory resources effectively, providing users with greater control and flexibility when working with memory-intensive applications.
This feature was introduced in #45369.
Sorting performance
Lilith Hafner
The default sorting algorithm has been upgraded to a more adaptive sorting algorithm that is always stable and often has state of the art performance. For simple types and orders—BitInteger, IEEEFloat, and Char sorted in default or reverse order—we use a radix sort that has linear runtime with respect to input size. This effect is especially pronounced for Float16s which received a 3x-50x speedup over 1.8.
For other types, the default sorting algorithm has been changed to the internal ScratchQuickSort in most cases, which is stable and generally faster than QuickSort, although it does allocate memory. For situations where memory efficiency is crucial, you can override these new defaults by specifying alg=QuickSort.
To learn more about the these changes, you can watch the JuliaCon 2022 talk, Julia's latest in high performance sorting and it's forthcoming sequel in JuliaCon 2023.
Tasks and the interactive thread pool
Jeff Bezanson, Kiran Pamnany, Jameson Nash
Before version 1.9, Julia treated all tasks equally, running them on all available threads without any distinction in priority. However, there are situations where you may want certain tasks to be prioritized, such as when running a heartbeat, providing an interactive interface, or displaying progress updates.
To address this need, you can now designate a task as interactive when you Threads.@spawn it:
using Base.Threads
@spawn :interactive f()You can set the number of interactive threads available using the following command:
julia --threads 3,1This command starts Julia with 3 "normal" threads and one interactive thread (in the interactive thread pool).
For more information, refer to the manual section on multi-threading. This feature was introduced in #42302 .
REPL
Contextual module REPL
Rafael Fourquet
In Julia, the REPL evaluates expressions within the Main module by default. Starting with version 1.9, you can now change this to any other module. Many introspection methods, such as varinfo, which previously defaulted to examining the Main module, will now default to the REPL's current contextual module.
This feature can be particularly useful when developing a package, as you can set the package as the current contextual module. To change the module, simply enter the module name in the REPL and execute Meta+M (often Alt+M), or use the REPL.activate command.
julia> @__MODULE__ # Shows module where macro is expanded
Main
# Typing Base.Math and pressing Meta-m changes the context module
(Base.Math) julia> @__MODULE__
Base.Math
(Base.Math) julia> varinfo()
name size summary
––––––––––– ––––––– –––––––––––––––––––––––––––––––––––––––––––––
@evalpoly 0 bytes @evalpoly (macro with 1 method)
Math Module
^ 0 bytes ^ (generic function with 68 methods)
acos 0 bytes acos (generic function with 12 methods)
acosd 0 bytes acosd (generic function with 1 method)
acosh 0 bytes acosh (generic function with 12 methods)
acot 0 bytes acot (generic function with 4 methods)
...Numbered prompt
Kristoffer Carlsson
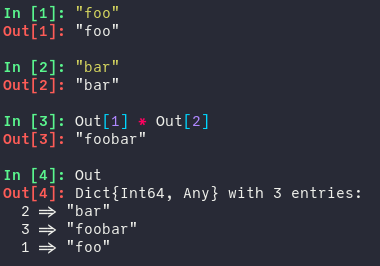
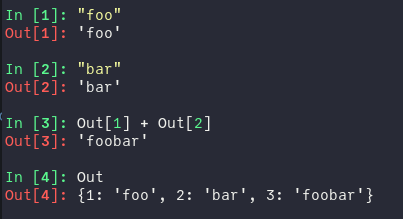
Drawing heavily on inspiration from the IPython shell (and other notebook-based systems like Mathematica), the Julia REPL can enable a "numbered prompt" that stores evaluated objects in the REPL for later use and keeps track of the number of expressions that have been evaluated.
Being able to refer to an earlier evaluated object can be useful if, for example, one forgets to store the result of a long computation to a variable and then executes something else (so that ans gets overwritten).
 |  |
|---|---|
| Julia REPL with "numbered prompt" | IPython REPL |
For instructions how to enable this, see the documentation.
DelimitedFiles – first stdlib to be upgradable
Kristoffer Carlsson
Julia comes with a set of standard libraries ("stdlibs") which are similar to normal packages except that they can be loaded without having to explicitly install them. Most of these stdlibs also comes "prebaked" in the sysimage that Julia ships which means that they technically get loaded every time Julia is started.
However, this approach has some drawbacks:
The stdlib versions are tied to the Julia version, requiring users to wait for the next Julia release to receive bug fixes for them.
Prebaking stdlibs into the sysimage incurs a cost for users who don't utilize them, as they are loaded every time Julia starts.
Developing stdlibs that are in the sysimage can be annoying.
In 1.9 we are experimenting with a new concept of "upgradable stdlibs" that come shipped with Julia but can also be upgraded like normal packages. To start with, this is done with the small and relatively sparsely used stdlib DelimitedFiles.
Starting with a fresh Julia install, we can see that the DelimitedFiles package is loadable and that it is loaded from the Julia installation:
julia> using DelimitedFiles
[ Info: Precompiling DelimitedFiles [8bb1440f-4735-579b-a4ab-409b98df4dab]
julia> pkgdir(DelimitedFiles)
"/Users/kc/julia/share/julia/stdlib/v1.9/DelimitedFiles"However, when DelimitedFiles is added with the package manager a versioned version is installed that is loaded just like a normal package:
(@v1.9) pkg> add DelimitedFiles
Resolving package versions...
Updating `~/.julia/environments/v1.9/Project.toml`
[8bb1440f] + DelimitedFiles v1.9.1
Updating `~/.julia/environments/v1.9/Manifest.toml`
[8bb1440f] + DelimitedFiles v1.9.1
Precompiling environment...
1 dependency successfully precompiled in 1 seconds. 59 already precompiled.
julia> using DelimitedFiles
julia> pkgdir(DelimitedFiles)
"/Users/kristoffercarlsson/.julia/packages/DelimitedFiles/aGcsu"--math-mode=fast disabled
--math-mode=fast is now a no-op (#41638). We came to the conclusion that a global fastmath option is impossible to use correctly in Julia. For example it can lead to surprises such as exp returning completely the wrong value as reported in #41592. Combining a runtime fast-math option with precompilation and constant propagation leads to inconsistencies unless we accept the cost of an entirely separate system image.
Users are encouraged to use the @fastmath macro instead which constrains the effects of fastmath to a small piece of code.
Pkg
pkg> up Foo will now try to only update Foo
Kristoffer Carlsson
Previously it was underspecified what packages were actually allowed to upgrade when giving a specific package to update (pkg> up Foo). Now up Foo only allow Foo itself to update with all other packages having their version fixed in the resolve process. It is possible to loosen this restriction with the various --preserve command options to also allow e.g. dependencies of Foo to update. See the documentation for Pkg.update for more information.
pkg> add will only auto update the registry once per day
Kristoffer Carlsson
Pkg will now remember the last time the registry was updated across julia sessions and only auto-update once per day when using an add command. Previously the registry auto-updated once per session. Note that the update command will as before always try to update the registry.
pkg> add can now try to only add already installed packages
Ian Butterworth
When working with many environments, for instance across Pluto notebooks, the default behavior of Pkg.add to add the latest version of the requested package and any new dependencies can mean hitting precompilation frequently.
Pkg.add can now be told to prefer to add already installed versions of packages (those that already have been downloaded onto your machine), which are more likely to be precompiled.
To globally opt-in to the new preference set the env var JULIA_PKG_PRESERVE_TIERED_INSTALLED to true.
Or to enable for specific operations use:
pkg> add --preserve=tiered_installed Footo try this new strategy first in the tiered preserve.pkg> add --preserve=installed Footo strictly try this strategy, or error.
Note that using this you may get old versions of packages installed so if you are encountering issues, it is usually a good idea to do an actual upgrade to the latest version to see if the issue has been fixed.
pkg> why to tell you why a package is in the manifest
Kristoffer Carlsson
To show the reason why a package is in the manifest a new pkg> why Foo command is available. The output is all the different ways to reach the package through the dependency graph starting from the direct dependencies.
(jl_zMxmBY) pkg> why DataAPI
CSV → PooledArrays → DataAPI
CSV → Tables → DataAPI
CSV → WeakRefStrings → DataAPIpkg> test --coverage (the default for CI) is now faster
Ian Butterworth
Previously, coverage testing could only be enabled for either all where all code visited is checked, user (the prior default for Pkg.test) where everything except for Base is checked including stdlibs, or none where tracking is disabled.
The github action julia-runtest defaults to coverage testing on, meaning a lot of tracking outside of the package under test previously took place, slowing tests down, especially tight loops.
v1.8 introduced the ability to specify a path to either a file or directory for coverage to be tracked in via --code-coverage=@path, and v1.9 makes that the default for Pkg.test(coverage=true) (and thus used by julia-runtest by default).
This change means often a lot less code needs to be tracked, and in cases where code from dependencies fall in tight loops this can heavily speed up the test suite. In one example Octavian.jl tests with coverage enabled went from >2hrs to ~6 minutes.
Better support for sub-packages in monorepos via the manifest field in Project.toml
Jacob Quinn, Nick Robinson
Pkg will now support a manifest = "path/to/Manifest.toml" field, which simplifies the package management experience for projects that are organized with smaller sub-packages in the same repository. While Base loading previously supported specifying a custom manifest in the Project.toml file, Pkg.jl was unaware and didn't take this configuration into account. With this change, "monorepo" style projects can have their sub-projects (internal packages) specify a root-level manifest to "share" dependency resolution and versions. This greatly simplifies Pkg operations on sub-projects because they don't need their own Manifest.toml files that can quickly get out of sync with the parent or peer manifests.
Apple Silicon Achieves Tier 1 Status
With all tests successfully passing and continuous integration (CI) established for Apple Silicon, the platform's status has been upgraded from Tier 2 to Tier 1.
LLVM Update to v14
Valentin Churavy, Mosè Giordano
LLVM is the underlying compiler infrastructure that Julia's compiler builds upon. With Julia 1.9 we update the version used to v14.0.6.
Among the other features introduced in LLVM 14 there is autovectorization enabled by default for SVE/SVE2 extensions on AArch64 CPUs. SVE, Scalable Vector Extension, is a SIMD-like extension which uses flexible-width vector registries, instead of the fixed-width registries typically used by other SIMD architectures. Julia code does not have to do anything to use SVE/SVE2 instructions: vectorizable code always uses SIMD instructions when possible, and with LLVM 14 the SVE registries will be used more aggressively on CPUs which support it, such as Fujitsu's A64FX, Nvidia Grace, or the ARM Neoverse series. We gave an overview of Julia SVE autovectorization capabilitites in the webinar Julia on A64FX.
Native half-precision floating-point arithmetic
Gabriel Baraldi, Mosè Giordano
To execute arithmetic operations on Float16 values, julia used to promote them to Float32, and then convert them back to Float16 to return the result. 1.9 added support for native Float16 operations on AArch64 CPUs that have hardware support for half-precision floating-point arithmetic, like Apple's M series or Fujitsu's A64FX. In memory-bound applications this allows for up to 2× speedup compared to Float32 operations and 4× compared to Float64 operations. For example, on an M1 MacBook you can get
julia> using BenchmarkTools
julia> function sumsimd(v)
sum = zero(eltype(v))
@simd for x in v
sum += x
end
return sum
end
sumsimd (generic function with 1 method)
julia> @btime sumsimd(x) setup=(x=randn(Float16, 1_000_000))
58.416 μs (0 allocations: 0 bytes)
Float16(551.0)
julia> @btime sumsimd(x) setup=(x=randn(Float32, 1_000_000))
116.916 μs (0 allocations: 0 bytes)
897.7202f0
julia> @btime sumsimd(x) setup=(x=randn(Float64, 1_000_000))
234.125 μs (0 allocations: 0 bytes)
1164.2247860232349Milan Klöwer presented an application of using half-precision for a shallow water simulation run on A64FX in his JuliaCon 2021 talk 3.6x speedup on A64FX by squeezing ShallowWaters.jl into Float16.